Linux程序兼容性疑难解答(Everything与SpaceSniffer篇)
迁移到Linux后,我非常想念Everything。
只要稍加一些想象力,Everything的用途可远远不止按文件名搜索。我用它做这些事:
- 快捷启动软件。无论是安装型软件还是绿色软件,无论安装到了哪里,只要输入软件名(快捷方式文件名)或EXE文件名就能立刻打开。它还会记忆各文件打开次数,便于更快定位到常用项目。我几乎再也不使用、也不需要管理桌面快捷方式和开始菜单了。
- 寻找软件的安装路径。同上。
- 寻找离线文档。很多软件会把文档安装到硬盘上,但只能通过特定方式访问,如
rustup doc、texdoc,结果用户要么根本不知道有离线文档,白白浪费了硬盘空间,要么在需要时不记得启动命令,还不如搜索在线文档方便快捷。Everything能聚合搜索全部已安装软件留下的文档文件名。 - 检查软件正在干什么。比如说,当我不知道某些流浪猫软件把模型下载到哪里去了的时候,可以趁下载过程中打开Everything,将全盘文件按修改时间排序,正在逐渐变大的那个文件一定就是了。当然这只能检查硬盘上没有被刻意屏蔽掉的动作(软件可能故意不更新文件修改时间),不过已经足够泛用了。
- 操作扁平化的文件夹。列出指定文件夹的全部文件或筛选部分文件,然后就可以跳过目录层级,只对这些文件进行操作。比如说,可以图形化地实现
mv **/*.pdf ~/Library这样的操作。 - 寻找大文件。按大小排序只看单个文件的大小,与SpaceSniffer、TreeSize等软件的思路不同,可以搭配使用。
- 寻找手边的测试文件。例如全盘搜索*.mp4文件用来测试视频上传功能等。
- 检测你电脑上有几个CEF 😾
这些是我现在能想起的用途。Everything既有速度又有实时性,让许多原本运行代价高昂的操作方式变为了可以日常使用的高效流程。只要问题能化归为按某些条件查找文件元数据,就总是能立即给出结果;只要搜索条件足够精确,就无需指定在何处扫描。
Everything的原理是读取NTFS MFT和USN日志,自行构建和更新文件信息数据库。
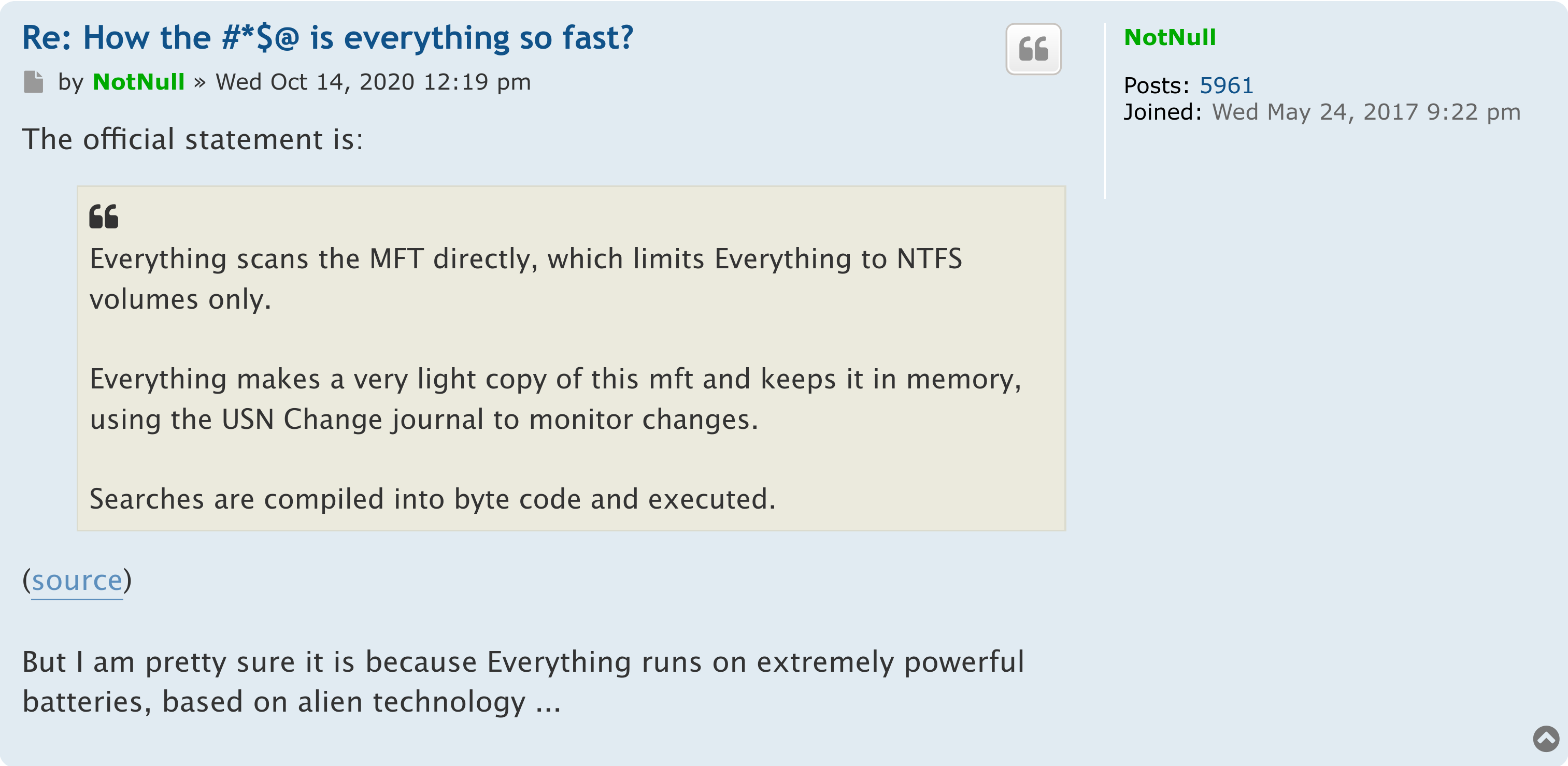
因为没有主流文件系统原生支持全盘搜索,所以,要做到瞬间完成搜索,自有数据库必不可少。Linux上,思路类似的工具我只找到locate系列和FSearch。然而,它们都为了搜索速度牺牲了实时性,要搜索新文件必须先等待建立索引。在我的电脑上,FSearch索引约200万个文件需要30秒。而且它们目前都较少有功能更新与维护。
要做到实时搜索,可以读取文件系统日志或利用操作系统提供的监听修改接口。Windows是这样的,Everything只要支持NTFS就行了,而Linux要考虑的事情就很多了。由于Linux支持的文件系统多样,读取文件系统日志的开发成本较高,我没有找到哪个软件走这条路线。而Linux提供的用户级监视功能inotify需要为每个目录分别建立监听,效率很低,且有上限,无法用于监视全盘。KDE的搜索功能为此还会特地提示用户增加上限。
我没有想到的是,时至今日,就算不建数据库,暴力扫盘也可以很快!
在我的电脑上,find搜索全盘需要十几秒,而fd带-u(不要忽略隐藏文件等)硬扫全盘也只需要不到1秒 
根本原因在于,新时代的硬盘已经不像以前那么慢了。在机械硬盘上如此之快,体现了Everything的实力;在固态硬盘上要达到同样的效率,只需要回归暴力。NVMe固态硬盘的顺序读取速度量级可达GB/s,随机读取性能也不差。更重要的是,如今的固态硬盘支持并行处理。
fd使用的递归遍历核心代码来自ripgrep作者BurntSushi开发的ignore crate中的WalkParallel对象。我写了个用它统计文件数量的小程序测试了一下,结果发现,只要当调包侠,就可以把遍历全盘的耗时压到1秒以内。
代码
use ignore::WalkBuilder;
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
fn main() {
let count = Arc::new(AtomicUsize::new(0));
WalkBuilder::new("/")
.standard_filters(false)
.build_parallel()
.run(|| {
let count = Arc::clone(&count);
Box::new(move |entry| {
if entry.is_ok() {
count.fetch_add(1, Ordering::Relaxed);
}
ignore::WalkState::Continue
})
});
println!("{}", count.load(Ordering::Relaxed));
}这当然不是Rust的专利,各种为并行提供良好支持的语言都能实现这种加速。Go语言写的fzf自带的文件名搜索依靠并行获得了基础速率提升,至少能打过find。gdu比功能相似的ncdu快十倍,同样是并行所赐。在我的电脑上,Windows上用SpaceSniffer扫盘的耗时是分钟级;ncdu扫全盘需要40秒,而gdu只需要4秒。我的硬盘在Windows上的时候塞得更满,与Linux比较不完全科学,但至少说明SpaceSniffer还有提速的空间。
虽然不停地暴力扫盘并不是解决实时性问题的真正方法,但已经足以应对大部分先查询后使用的场景了。