北大编译原理课程实验报告
这个学期,我做了PKU编译原理课程实验。
北大的编译原理课程广受好评,助教MaxXing功不可没。他制作了从设计文档到评测系统的一系列课程配套实验设施,并在GitHub上公开。
实验的目标是制作SysY(C语言子集)到RISC-V的编译器。受支持的实现语言有C、C++、Rust,其他语言理论上也可以使用但不提供支持。我以前第一次想尝试的时候,还不会Rust,于是被劝退:
我们不建议之前从未接触过 Rust, 对内存管理/所有权等概念不敏感, 且对自己编码水平没什么信心的同学使用 Rust 开发编译器. 对这些同学来说, 在编译实践中上手 Rust 可能会比较痛苦.
现在,我对C++的憎恨丝毫不灭,但我已经升级为“之前接触过Rust,且对Rust感兴趣的同学”了。
还有一个劝退因素是,运行评测环境的唯一方式是Docker,但我因为各种原因很讨厌Docker。容器就一定要这么难用吗?!后来我换用了Podman,虽然还是很讨厌,但至少它不刚需root权限,也就不会在挂载点里乱拉所有者为root的文件,印象稍微好那么一点点。
所以我又一次踏上了编译原理之旅,以下是旅途中的见闻记录。
Lv1. main函数
Lv1.2. 词法/语法分析初见
此处我们只处理了形如
// ...的行注释, 你需要自行处理形如/* ... */的块注释. 块注释也可以用正则表达式表达, 但会稍微复杂一些.
初学者第一喜欢的懒惰匹配法\/\*.*?\*\/被LALRPOP封死了,原因竟然是不知道 😾
我给出的答案是嵌套重复匹配\/\*([^*]*\*+)+\/ 😈️ 基于回溯的正则表达式引擎处理这类模式有死机风险:
$ node -v
v25.9.0
$ time node -e '/\/\*([^*]*\*+)+\//.exec("/****************************")'
real 0m6.037s
user 0m5.998s
sys 0m0.015sLALRPOP的匹配引擎基于regex-automata,保证线性时间复杂度,可以安全处理嵌套重复匹配,写成这样也没问题。
原以为习题应该没这么复杂,没想到参考答案更离谱:
r"/\*[^*]*\*+(?:[^/*][^*]*\*+)*/" => {},这个正则表达式明确要求连续*之间要有至少一个无关字符([^/*])才会激活重复匹配,不会产生指数爆炸,因此即使是基于回溯的引擎也能高效处理。
我额外追加了0b开头的二进制和0o开头的八进制整数字面量的支持。这好像已经成了每期编译原理作业的定番了。瞧一瞧,看一看,免费的创新点!
IntegerLiteral: i32 = {
r"[1-9][0-9]*" => i32::from_str(<>).unwrap(),
r"0[xX][0-9a-fA-F]+" => i32::from_str_radix(&<>[2..], 16).unwrap(),
r"0[0-7]*" => i32::from_str_radix(<>, 8).unwrap(),
r"0[oO][0-7]+" => i32::from_str_radix(&<>[2..], 8).unwrap(),
r"0[bB][01]+" => i32::from_str_radix(&<>[2..], 2).unwrap(),
}Lv1.5. 测试
如果采用文档中介绍的docker run --rm …来运行评测脚本,容器用后即毁,导致每次运行都要从零开始重新下载依赖和编译整个项目。网络不好是我的问题,没有编译缓存却是影响所有人开发效率的大问题。对Rust来说,有无编译缓存,编译速度可是天壤之别。
Docker方便了在线评测机的部署,却也导致了本地评测还不如提交到在线评测平台方便。当然,因为我没有在线评测平台的账号,只能本地运行评测系统了。从课程资料公开之初就有人问能不能向没有选课的同学开放评测平台,竟然不许!
为了加速评测编译,我创建了命名容器:
# 首次使用,创建容器
podman run --name sysy -it -v .:/root/compiler docker.io/maxxing/compiler-dev bash
# 再次使用,启动容器
podman start -ai sysy这样可以保留依赖下载缓存。
评测脚本默认在临时目录中运行,需要用-w选项指定工作目录才能保留编译缓存:
autotest -koopa -w build -s lv1 compilerLv2. 初试目标代码生成
Lv2.2. 目标代码生成
哈哈,![]()
指令的数据并没有直接按照指令出现的顺序存储在列表中. 指令的数据被统一存放在函数内的一个叫做
DataFlowGraph的结构中, 同时每个指令具有一个指令 ID (或者也可以叫 handle), 你可以通过 ID 在这个结构中获取对应的指令. 指令的列表中存放的其实是指令的 ID.这么做看起来多套了一层, 但实际上 “指令 ID” 和 “指令数据” 的对应关系, 就像 C/C++ 中 “指针” 和 “指针所指向的内存” 的对应关系, 理解起来并不复杂. 至于为什么不直接把数据放在列表里? 为什么不用指针或者引用来代替 “指令 ID”? 如果对 Rust 有一定的了解, 你应该会知道这么做的后果…
虽然理解起来不复杂,但这导致需要传递的参数变多了。一刻也没有为[分段:地址]的死亡哀悼,立刻来到内存的是arena!
教程推荐定义名为GenerateAsm的单方法接口,并为Program、FunctionData、ValueData(即IR指令,因为采用SSA所以名为Value)等对象各自实现该接口,来实现遍历IR树和生成汇编代码,类似访问者模式(visitor pattern)。访问者模式解决了OOP ADT遍历问题,可是Rust有enum啊?既然没有利用接口进行泛型处理的需要,甚至不同对象生成代码需要的参数都可能不同,我对是否真的应该定义接口存疑。
由Program生成汇编只需要Program(废话);函数间各自独立,由FunctionData生成汇编也只需要FunctionData。然而,由ValueData生成汇编同时需要ValueData和FunctionData两者数据:ValueData表示的指令可能引用其他指令,在结构体中只保存被引指令的句柄*,需要拿到整个函数的数据才能取得被引指令的内容。
连参数数量都不同的同名方法要怎么硬塞到一个接口里呢?我没理解这个推荐的接口的签名要怎么写,便简单直接地写了三个函数emit_program、emit_function、emit_value。
我必须平等地攻击所有滥用设计模式的行为!在参考答案中,GenerateToAsm::generate方法操作全局状态,在全局状态中记录当前正在处理的函数;因为操作全局状态,签名里塞了一堆生命周期标记;返回值也随处理对象不同而不同:
use super::info::ProgramInfo;
use std::fs::File;
use std::io::Result;
pub trait GenerateToAsm<'p, 'i> {
type Out;
fn generate(&self, f: &mut File, info: &'i mut ProgramInfo<'p>) -> Result<Self::Out>;
}如此复杂到失去抽象作用的接口究竟是何意?
Lv3. 表达式
Lv3.1. 一元表达式
随着深入使用Koopa IR,我开始对其设计感到极为不解。
指令列表用专为此用途设计的散列表 + 双链表数据结构存储(key-node-list crate)。众所周知,Rust中编写链表非常困难,使用其他数据结构不仅更好写,性能往往也更好。我不明白为什么要用双链表,可能是受到LLVM遗留的影响。
KeyNodeList的API设计也十分诡异。push_key_back方法返回Result<(), K>,强制调用方处理列表元素重复的异常。为什么不像标准库的HashMap那样,返回Option<K>?然而extend方法返回的却是()。异常哪去了?被吃了 😾
fn extend<I: IntoIterator<Item = (K, T)>>(&mut self, iter: I) {
iter.into_iter().for_each(|(k, n)| {
let _ = self.push_back(k, n);
});
}想必是因为用起来实在太啰嗦,参考答案提取出了push_bb和push_inst_to函数。
/// Pushes the basic block to the function,
/// updates the current basic block.
pub fn push_bb(&mut self, program: &mut Program, bb: BasicBlock) {
program
.func_mut(self.func)
.layout_mut()
.bbs_mut()
.push_key_back(bb)
.unwrap();
self.cur = bb;
}
/// Pushes the instruction to the back of the given basic block.
pub fn push_inst_to(&self, program: &mut Program, bb: BasicBlock, inst: Value) {
program
.func_mut(self.func)
.layout_mut()
.bb_mut(bb)
.insts_mut()
.push_key_back(inst)
.unwrap();
}IR指令中的立即数在内存中以Integer指令的形式存在,比如ret 114514实际上是%0 = int 114514和ret %0两条指令。但与其他指令不同,Integer指令不得加入指令列表,会报错“can not name constants”。Integer指令被其他指令引用,却不出现在指令列表中,处于灰色地带。KoopaGenerator对Integer指令做了特殊处理,使其在文本形式IR中显示为内联的立即数。
除了Integer,其他类型的指令也可以不出现在指令列表中却被其他指令引用。这可能是未明确定义的行为,或者是为了方便操作而允许的中间状态;合法IR指令列表应该按计算顺序拓扑排列。KoopaGenerator不会输出处于灰色地带的指令,只会给它们编号,结果便是产生类似下面这样不合法的文本形式IR。
fun @main(): i32 {
%entry:
ret %0
}从这一点上来看,Integer指令与其他指令没有任何共通行为,将其作为一种指令类型对待毫无道理。
如果生成汇编时只看指令间引用关系而不看指令列表,把IR当成树而非列表来用,其实也能生成可行的汇编,并通过RISC-V测试(见提交f5b33135 3.1?)。但不正确生成和处理指令列表的话,无法通过Koopa测试,也难以应对之后要用到的有副作用的指令。
Lv3.3. 比较和逻辑表达式
做到这里,应该会发现koopa::ir::BinaryOp只剩三种情况没有处理了:Shl、Shr、Sar。SysY语言没有位运算,这三种指令在整个教程主线中一次都不会用到。另外,And和Or指令也只被用于实现&&和||。
Crafting Interpreters同样选择了避开位运算。我想原因之一是实现对象Lox是一门高级脚本语言,唯一数值类型是浮点数,位运算与语言性质不合。Lua 5.2就是如此,语言不内置位运算符,而是作为标准库函数提供。
而另一个原因,则是位运算位于C系语言语法和语义最黑暗的一面。Crafting Interpreters花了一篇专栏来讲述&和|的优先级问题对语言设计的影响。C语言的位移与整数提升交织,还充满了未定义行为和实现定义行为。SysY作为C子集,引入位运算势必带来复杂的语义。也许Java把>>拆成>>和>>>真的是对的?
Lv4. 常量和变量
Lv4.1. 常量
SysY支持像const int a = 114, b = 514;这样,在一句常量语句中有多个同类型常量定义。与直接反映语法、在单条语句中保存多个ConstDef的参考答案AST不同,我的AST的常量语句只支持一个常量,源代码中的一句常量语句在解析时脱糖为多句常量语句。
在解析阶段脱糖,可以免去为语法糖设计AST的麻烦。然而因为使用了解析器生成器,解析器相关代码位于LALRPOP文件中,缺乏编辑器自动补全等支持,难以在其中编写复杂逻辑。这便是现如今DSL的悲惨境遇。
Lv4.2. 变量和赋值
SysY语言做了个违背C语言祖宗的决定:赋值是语句,不是表达式。没有补偿的话,像a = b = 114514;这样的连续赋值语法就不能用了。虽然这个选择不能说是错误,但是它直接导致Lv6.2无法立即得到测试。
早在编写Lv3.1的代码时,我就预览了本节的内容。如果没有这样做,到这里就会发现,当时写的垃圾寄存器分配策略现在要推翻重做 😾
虽说是分配栈内存,但Alloc指令与其他算术指令的返回值同样是32位整数,得益于寄存器分配策略摆烂,这些值本来就在栈上可读可写,完全不需要特殊处理——我的Alloc指令实现如下。
- koopa::ir::ValueKind::Alloc(_) => todo!(),
+ koopa::ir::ValueKind::Alloc(_) => Ok(()),
Lv5. 语句块和作用域
Lv5.1. 实现
写到这里才发现,我在实现常量和变量声明语句时,完全没有处理名称重复定义的情况。也就是说,下列程序在我的编译器中是合法的。因为测试不包含非法输入,一直没有发现这个bug。
int main() {
int a = 114;
int a = 514;
return a;
}这倒是为我偷懒不做层叠作用域数据结构提供了便利。我直接在遇到新语句块时复制一份新的作用域,内部变量自然能遮蔽外部变量。你就说是不是实现了作用域吧,至于效率高不高你别问 😾
ast::Statement::Block(statements) => {
let mut scope: HashMap<String, ScopeItem> = scope.clone();
for statement in statements {参考答案使用类似原型链的做法,在最内层引用最外层变量时查找效率达到最坏的O(层数),其他操作均为O(1)。考虑到作用域嵌套一般不会很深(特别是过程式语言),这个选择很合理。
有没有所有操作都优于线性的层叠作用域数据结构呢?不妨试试 hash array mapped trie(逃
Lv6. if语句
Lv6.1. 处理if/else
LALRPOP的报错好得离谱。请看VCR:
processing file `/home/satgo/λ/src/grammar.lalrpop`
/home/satgo/λ/src/grammar.lalrpop:66:5: 70:5: Ambiguous grammar detected
The following symbols can be reduced in two ways:
"if" "(" Expression ")" "if" "(" Expression ")" Statement "else" Statement
They could be reduced like so:
"if" "(" Expression ")" "if" "(" Expression ")" Statement "else" Statement
│ └─Statement─────────────────────┘ │
└─Statement──────────────────────────────────────────────────────────────┘
Alternatively, they could be reduced like so:
"if" "(" Expression ")" "if" "(" Expression ")" Statement "else" Statement
│ └─Statement──────────────────────────────────────┤
└─Statement──────────────────────────────────────────────────────────────┘
LALRPOP does not yet support ambiguous grammars. See the LALRPOP manual for advice on
making your grammar unambiguous.
/home/satgo/λ/src/grammar.lalrpop:66:5: 70:5: Conflict detected
when in this state:
Statement = "if" "(" Expression ")" Statement (*) [r#"0[0-7]*"#, r#"0[bB][01]+"#, r#"0[oO][0-7]+"#, r#"0[xX][0-9a-fA-F]+"#, r#"[1-9][0-9]*"#, r#"[_a-zA-Z][_a-zA-Z0-9]*"#, "!", "!=", "%", "&&", "(", ")", "*", "+", ",", "-", "/", ";", "<", "<=", "=", "==", ">", ">=", "const", "else", "if", "int", "return", "{", "||", "}", "~", Eof]
Statement = "if" "(" Expression ")" Statement (*) "else" Statement [r#"0[0-7]*"#, r#"0[bB][01]+"#, r#"0[oO][0-7]+"#, r#"0[xX][0-9a-fA-F]+"#, r#"[1-9][0-9]*"#, r#"[_a-zA-Z][_a-zA-Z0-9]*"#, "!", "!=", "%", "&&", "(", ")", "*", "+", ",", "-", "/", ";", "<", "<=", "=", "==", ">", ">=", "const", "else", "if", "int", "return", "{", "||", "}", "~", Eof]
and looking at a token `"else"` we can reduce to a `Statement` but we can also shift不过,其中提到的手册并不包含关于如何消除冲突的建议。
This tutorial is still incomplete. […]
Here are some topics that I aim to cover when I get time to write about them:
- Advice for resolving shift-reduce and reduce-reduce conflicts
悬空else的解法并不简单,不是很容易就能想到的。比起靠“提示: 拆分”“自行思考如何解决”,学生更可能通过点击“dangling else problem”来解决。
又遇到了通过了RISC-V测试却通不过Koopa测试的情况。这次是因为:
需要注意的是, 基本块的结尾必须是
br,jump或ret指令其中之一 (并且, 这些指令只能出现在基本块的结尾).
这一节是教程第一次说明这一点。于是学生的编译器很可能自从支持多种语句起,就没有特别处理不在函数末尾的return语句,会在基本块中间产生Return指令,但之前的测试没有暴露问题,拖到现在才有针对该情况的测试用例(testcases/lv6/6_multiple_returns.c)。
我的编译器总是在then/else块末尾插入Jump到if语句之后的指令,于是if (1) return 1;的then块会被编译为连续的Return和Jump指令,违反基本块结尾规则。
%main__bb7:
ret 1
jump %main__bb9我的解决方案是修改push_inst函数,如果基本块已经密封,就不再追加指令。Value没有提供确定是否只能在结尾使用的方法,我只好if let ir::ValueKind::Branch(_) | ir::ValueKind::Jump(_) | ir::ValueKind::Return(_) = …。
参考答案则是在每次插入跳转型指令后就创建一个新的基本块,因此不可达语句会被放到入度为零的基本块中。
%if_then:
store 1, %ret
jump %end
%1:
jump %if_end
// …
%end:
%3 = load %ret
ret %3Lv6.2. 短路求值
那我问你,φ节点呢?抄LLVM不抄全是吧 😾
这个没有测试、只有语义变化的小节是压缩毛巾 😾 一个表达式只属于一个基本块的性质被破坏。And和Or指令完成了它们的使命,从此没有用了。实现if语句只要在基本块间跳转就好了,可现在需要从分支里得到值。参考答案采用评论区的做法,用一个新的临时变量来接收两个分支的值。因为代码实在是太长了,参考答案又定义了个多达9个参数的generate_logical_ops!宏 😾
我用带参数的基本块实现基本块间参数的传递。这个功能属于Koopa IR的SSA扩展,在参考答案中从未使用。因为至多只有一个整数参数,生成汇编时,我选择将基本块参数保存在寄存器a0中,进入目标块时立即使用。这种做法截至目前能通过测试,但为后续Lv8.1表达式混合函数调用出错埋下了伏笔。
int main() {
return 114 || 514;
}fun @main(): i32 {
%entry:
br 114, %main__bb1, %main__bb2
%main__bb1:
jump %main__bb3(1)
%main__bb2:
%0 = ne 0, 514
jump %main__bb3(%0)
%main__bb3(%1: i32):
ret %1
}Lv8. 函数和全局变量
Lv8.1. 函数定义和调用
复杂返回值(返回结构体等)是个C-shaped hole 😾 我选择偷懒,令所有函数的返回值统一为i32,缺失return语句的函数返回0。
表达式仅使用少数寄存器的性质被函数调用破坏,调用函数可能需要写入a0 ~ a7,被调用函数可能随意写入临时寄存器。
Lv6.2提到,我的基本块参数采用寄存器传递,没有备份到栈上。短路求值与函数调用使用的寄存器冲突,导致复杂表达式计算结果错误。解决方法当然是像函数参数一样,把基本块参数也放到栈上。
函数可以有参数,基本块也可以有参数;一进函数就把参数放到栈上,一进基本块就把参数放到栈上;函数通过Return指令的参数来返回值,基本块通过Jump指令的参数来返回值。函数和基本块本是同根生,为何要区别对待呢?因为C-shaped hole 😾
私有函数的代码完全由编译器掌控,只要能正确传递参数,无论怎么传都可以,本来就无需遵循调用约定。调用约定的唯一意义是与操作系统和动态链接库交互。就算如此,也可以只在系统调用边界上转换调用约定(cosmopolitan libc在Windows上就是这么干的),而不是把系统的调用约定强加到语言上。
Lv8.2. SysY库函数
虽然 SysY 中可以不加声明就使用所有库函数, 但在 Koopa IR 中, 所有被
call指令引用的函数必须提前声明, 否则会出现错误.
注意是“提前”声明,把声明放在最后会报错 😾 这都什么年代了,还在要求函数拓扑排序?我的SysY实现允许调用之后定义的函数。如果输入程序没有按调用链拓扑排序,就会生成无效的IR,但能正确生成汇编 😾
由于Lv8.1完全没做void函数的支持,我偷偷把标准库函数返回值都定义成i32了。猜猜为什么谭浩强的void main()编译完能正常运行。
Lv8.3. 全局变量和常量
我好想把全局变量当成main函数的局部变量来处理啊。全局变量和局部变量究竟有什么区别呢?只有栈开得太小了的时候才体会得到吧 😾
可惜IR不让我这么干。简单地试图跨函数引用变量当然是不行的。不像指针只要解引用就能读,句柄虽然全局唯一,但没有记录其来自哪个函数,不知道所处函数就无法获取数据。就算内存中可以表示,转换到文本形式后也不可能通过Koopa测试。
不过没关系,IR偷不了懒,关我汇编什么事?汇编我想怎么生成就怎么生成!我在main函数开始时在栈上分配所有全局变量并初始化,用从未用过的fp寄存器记录这些变量的位置。
IR把全局值和局部值区分得很开,明明只是作用域不同,两者却几乎没有共通特性,结果就是逻辑难以复用,代码里充斥着像下面这样不得不写的判断。
let value = if value.is_global() {
&program.borrow_value(value)
} else {
dfg.value(value)
};我对不得不重新写一遍变量初始化逻辑表示很不满。而更令我不满的是,就在下一节,刚重写完的变量初始化几乎又要推翻重写 😾
Lv9. 数组
Lv9.1. 一维数组
整整八章没有出现过除i32以外的其他类型(void不算),都做到这里了再追加新类型,哈哈,好好玩,要爆了!
Haskell Core选择有类型IR,是因为Haskell的类型系统足够强,使其能够检查出编译器中的实现错误。C的类型系统很弱,编译C程序选择有类型IR,用处就小很多:前八章中的实现错误都无法通过类型系统检查出来。
我不相信照着教程做的学生能有足够的规划,像之前的章节那样增量地完成这一节。我写Lv9时进行了巨大修改才适应新增的类型,花费的时间可能比前面所有章节加起来都多 😾
这一节实在太庞大了,完全可以拆成多个小节,比如先实现只能填零/未定义的数组,再花一小节实现初始化列表。
由于基本类型只有i32和void(被我的编译器视作i32),实际类型完全由数组维度决定,所以我写出了这个极其抽象的语法定义:
Type ⩴ ("["Expression"]")∗
也就是说,关键字int起到了其他语言中关键字var的作用,真正的类型用方括号标注在变量名后面。
常量总是编译期内联的性质被破坏,现在需要根据维数判断常量究竟是编译期常量还是不能修改的变量。我原本想,反正IR不区分常量数组和变量数组,干脆把常量删了,彻底放弃常量内联优化。可是IR又要求数组大小是常量,编译期求值仍是必做的。
我最后选择在解析阶段把数组常量解析成变量定义。
Declaration ⩴"const"?"int"(VariableDefinition",")∗ VariableDefinition";"
事实上,C关键字const只是类型的一部分,用它定义的仍是变量而非常量,也不能用在数组维度中。在这一点上,SysY并非严格的C子集。C不像SysY在语法层面上就将常量与变量定义区分开来,语法更像是我所做的那样。
直到现在,我的编译器的数据模型里压根就没有指针的概念,无法合理实现GetElemPtr等指针操作指令,只好重构。所有通过Alloc分配的变量现在会在栈上预留变量自身加上一个指针的空间,Alloc指令也不再是什么都不做(参照Lv4.2),现在起到加载变量地址的作用。Load和Store指令现在会解引用指针。因此,使用变量的程序现在会生成比参考答案更复杂的汇编代码,占用的栈内存也更多。
┊ ┊
├──────┤
sp+12 │ %2 │
├──────┤
sp+ 8 │ %1 │
├──────┤
sp+ 4 │ %0 │
├──────┤
sp │ *@x │
└──────┘
┊ ┊
├──────┤
sp+28 │ ra │
├──────┤
sp+24 │ *@x │
├──────┤
sp+20 │ @x │
├──────┤
sp+16 │ %0 │
├──────┤
sp+12 │ %1 │
├──────┤
sp+ 8 │ %2 │
├──────┤
│░░░░░░│
├░░░░░░┤
sp │░░░░░░│
└──────┘
写Lv4.2时,我就很不理解,如果IR指令alloc T真的返回指针,而汇编只是机械解释IR的语义,那么参考答案生成的汇编为何没有体现出指针。去翻了一下参考答案的源码,发现原来是对Alloc指令有特判 😾
突然间,栈可以快速增长了,原先能用sp+偏移量寻址的栈帧内容,现在可能因超出可用偏移量范围而汇编失败。这一点早在Lv4.2就提到过:
- 需要注意的是,
addi指令中立即数的范围是 [−2048, 2047], 即 12 位有符号整数的范围. 立即数一旦超过这个范围, 你就只能用li加载立即数到一个临时寄存器 (比如t0), 然后用add指令来更新sp了.
但当时没有513个变量的测试用例,略过也不会发生问题。想必学生都是做到这里发现测试用例lv9/06_long_array.c无法通过才去补支持的吧 😾
global @zeroed_array = alloc [i32, 2048], zeroinit最后的最后, 你可能会问: 既然我能在全局数组初始化的时候使用 aggregate/
zeroinit, 那我能不能在局部变量初始化的时候也这么用呢? 答案是可以:@arr = alloc [i32, 5] store {1, 2, 3, 0, 0}, @arr
我原来以为可以的意思是可以alloc [i32, 5], zeroinit……什么叫可以store一个数组?什么叫可以store zeroinit, @arr?全局变量和局部变量之间,IR的设计究竟是怎么做到如此不一致的? 😾
不过,就算Alloc和GlobalAlloc的形式保持一致,全局数组和局部数组的初始化语义也有足够多的差异,导致处理逻辑根本没法复用。
我尝试用函数参数来抽象差异,但差异太多的同时又大量使用可变值,被Rust成功拦截 😾 于是回归复制粘贴。
fn initializer_to_value<
// 巨大泛型 😾
NewAggregate: FnMut(Vec<ir::Value>) -> ir::Value,
ExpressionToValue: FnMut(&ast::Expression) -> ir::Value,
>(
item: &ast::InitializerListItem,
mut new_aggregate: NewAggregate,
mut expression_to_value: ExpressionToValue,
) -> ir::Value {
match item {
ast::InitializerListItem::Value(expression) => expression_to_value(expression),
ast::InitializerListItem::List(items) => {
let values = items.iter().map(|item| {
initializer_to_value(item, &mut new_aggregate, &mut expression_to_value)
}).collect();
new_aggregate(values)
}
}
}let value = initializer_to_value(
&value,
|elems| func_data.dfg_mut().new_value().aggregate(elems),
|expression| lower_expression(func_data, bb, scope, expression),
//^^^^^^^^^ two closures require unique access to `*func_data` at the same time
);使用最新最热的Rust stable特性if let guard失败了,原因是这个特性今年2月刚合入,而Docker镜像内的rustc版本过低 😾
match expression {
ast::Expression::Variable(name) if let ScopeItem::Variable(value) = scope[name] => value,
ast::Expression::Element(array, index) => todo!(),
_ => panic!("invalid lvalue"),
}# rustc --version
rustc 1.91.1 (ed61e7d7e 2025-11-07)Lv9.2. 多维数组
如果你真的在Lv9.1只做了一维数组,那恭喜你完蛋了,这一节又要爆改。
从一开始就直接实现多维数组不比先做一维数组麻烦多少,多维数组独有问题只有初始化列表的怪语法。这种C-shaped hole有什么精读的必要吗 😾
但坏就坏在 C 语言这个初始化语法实在是太复杂了,不加限制的话很难写出一个在所有情况下都符合人类直觉的实现。更何况如你所说,编译器和编译器之间也有差异——事实上,对于 C/C++ 编译器而言,尤其后者,这种事情实在是太常见了,我能轻松举出十个这种例子。这也是我不建议初学者上来就接触 C/C++ 里过于拗口的语言细节的原因,它除了把你培养成一个语言律师以外,基本没什么好处。
因此,出于教学考虑,我觉得在未来应该进一步降低多维数组初始化语法的复杂度,加更多限制。
我写了几遍都写不好这神人初始化列表逻辑。最后发现,跳过IR关于值的形状要求,输出扁平数组直通汇编是最方便的。然而为了通过Koopa测试,我不得不把扁平数组组装成嵌套列表,再在生成汇编时拆回扁平数组。IR又成了阻碍 😾
Lv9.3. 数组参数
数组参数的出现,使得实参的语义变得很混乱:仅在计算参数时,如果得到的是数组,那么改为数组首元素的指针。多维数组索引到最后一维之前,计算出指针,但用光所有维度后则计算出值。
C数组参数传指针的语义,即使放在那个年代,也属于怪异的。这种C-shaped hole有什么重新实现的必要吗 😾
我原先的传参逻辑总是传值,没法从值还原回指针。最后,我实现数组退化的方式是先尝试将参数当成左值,如果得到的是数组,就取其首元素指针,否则按值传递。
数组[索引]的语义依数组的类型不同而不同,数组的场合用GetElemPtr指令实现,假数组真指针的场合则需要换成GetPtr指令。这导致需要在处理左值时获取方括号左侧值的类型。获取值的类型需要根据值位于全局还是局部,分别到程序顶层和函数数据流图中获取。我原以为开始处理函数内部后,就不再需要程序顶层的信息了,就没有把整个程序作为参数传下去,结果现在不得不爆改(4ca217f Thread &program through lower_*()) 😾
lv9/21_sort7.c竟然报了语法错误。检查后发现是return;语句的问题。此前return语句总是带值返回,这是测试用例中第一次出现不带值的return语句。这应该是Lv8.1追加的语法,但那一节完全没有提到这个变化,只在Lv8概览中提到了一下。追溯发现Lv5 ~ Lv7的语法规范也出现了不带值的return语句。我已PR修复了这个问题(#114)。
Lv9.4. 测试
我的编译器现在能通过所有130个Koopa测试,但是在运行RISC-V性能测试时,QEMU竟然报段错误崩溃了!
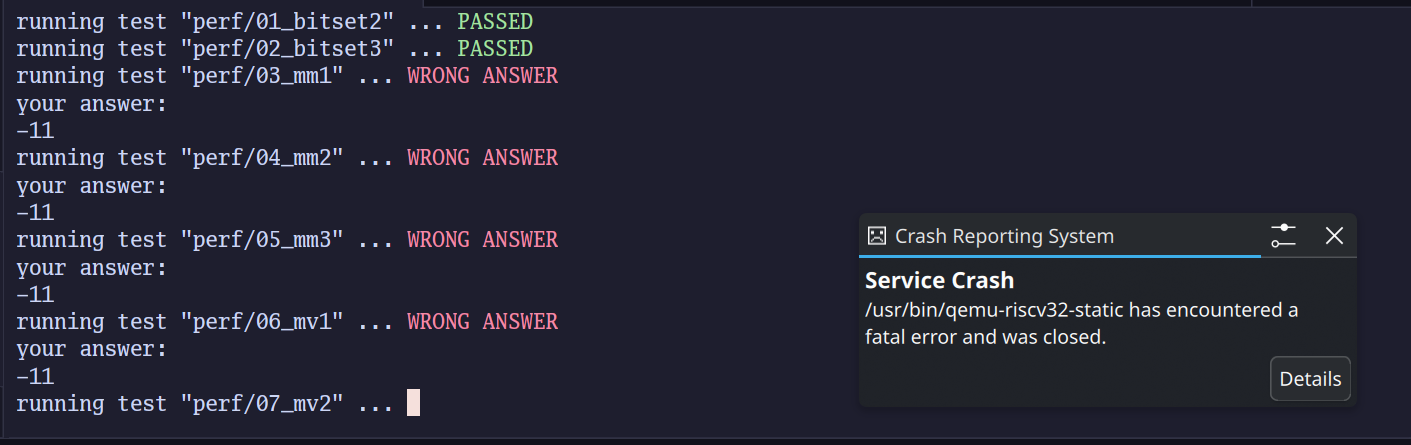
我承认,因为我的编译器总是把数组初始化循环展开成线性流程,为了全零初始化几个4MB的数组,生成了109MB的汇编和37MB的可执行文件,确实有点太炸裂了。
我把全零数组初始化改成循环了。对于这种编译器自动生成的、没有用户代码的小循环,1f和1b这样的临时标签很有用,好处在于不需要担心名称重复的问题。
li t2, 4194304
addi t2, t1, t2
1:
sw x0, (t1)
addi t1, t1, 4
blt t1, t2, 1b这解决了测试在汇编阶段耗时过长的问题,但崩溃仍没有消除。问题的关键应该在于栈不够大 😾 perf/15_transpose0.c ~ 17_transpose2.c开了个80MB的数组。明明都是内存,为什么操作系统就是不肯让大数组留在栈上呢?解决方法也很简单,把栈大小限制😾掉:
ulimit -s 114514然后就通过了所有130个RISC-V测试。
Lv9+. 新的开始
实验环境使用说明
只是在运行更多测试!
我运行了jokerwyt/sysy-testsuit-collection,找到了一些实验环境测试用例没有测出来的bug。
-
我在Lv1.2写的多行注释正则
\/\*([^*]*\*+)+\/有大问题:因为贪婪匹配了[^*]*,如果全程序有多处多行注释,会把*/~/*中间的代码也丢弃。解决方法是更长的正则 😾r"/\*/*(([^*/]|[^*]/+)*\*+)+/" => {}, -
我的编译器竟然在不支持初始化列表包含非常量的情况下通过了全部实验环境测试用例 😾 我也没想到我的编译器编译下列程序时,会因IR强制要求Aggregate内容为常量而报错:
int main() { int a = 114514; int b[1] = {a}; }反正局部数组的初始化因为这个原因都要转成索引赋值,那Store指令支持Aggregate岂不是毫无用处 😾
-
提前返回,其后定义的变量不会生成Alloc指令,再往后引用该变量时,因找不到Alloc指令而报错。这是因为Lv6.1应IR要求而添加的基本块结尾密封处理。由于Return必须在结尾,而Alloc的顺序没有影响,我选择把Alloc放到基本块开头。
-
超过520个参数时汇编失败,因为超出了寻址偏移量上限2047。神人测试用例,什么叫一个函数有一万个参数 😾 我选择不修。
-
lvX/matrix_1.c(求逆矩阵)的输入有10行10列,即使用货真价实的
gcc -O3编译出的原生程序也要运行1秒。我的编译器编译出的汇编太烂,还隔着一层模拟器运行,速度实在是太慢了,超时了 😾 我选择不修。
Lv9+.1 你的编译器超强的
我运行了awesome-sysy中的程序。只有mandelbrot.c需要一些特殊操作才能运行。外部函数声明实现起来很简单,核心逻辑只需要加一行。编译fp-math.c时,因为搞不懂怎样链入软件浮点库,我偷偷启用了RV32F扩展。

完结撒花 💮
必选章节写了三周。Lv9+.2及之后的可选章节我就不写了,已经吃得够多了 😾 前面的区域以后再来坍缩吧!
Lv9+.6. 向着更远处进发
TODO: 待补充.
测评
各位观众朋友们大家好,我是从来不带节奏的金色小松鼠,欢迎收看编译原理测评第2期北大编译原理课程实践测评。
先说结论,北大编译原理课程实践的泛用性较低,对策性一般,总的来说强度属于大杯。该教程的优势区间主要集中在:
- 实现语言可选C、C++、Rust,目标语言SysY基本上是C语言子集,学生很熟悉;
- 分步推进、持续测试的模式保证了最终能做出符合规范的可用的编译器;
- 提供了完善的实验环境、配套资料、测试用例、示例程序,还有往届学生贡献的更多资源、助教和社区用户帮助答疑;
- 中文,语言风趣,通俗易懂。
劣势区间在于:
- 输入语言、目标语言、实现语言的选择或设计均不尽人意;
- 部分章节安排/划分不合理;
- 教程给定语言规范但对实现细节放任不管,不清楚如何实现时只能阅读参考编译器源码或额外资料。
先介绍一下教程的整体思路。教程选择尽早打通编译器的整条链路,随后同步更新前中后端,每一章结束后的编译器都能完整运行并通过截至本章的所有测试。这相比传统教科书式的先在解析器理论的世界里磨叽半个学期,小测验提问“语法树有四种定义方法,你知道么?”*,临近期末暖机启动完毕天降机器码,卖家秀编译器突然就可以运行了,学生痛饮洗脚水的安排要好太多了。
章节拆分总体均匀,但也有不合理之处。按理说,尽早打通链路,就能尽快产生正反馈。但是在教程的条件下,在学生尚未掌握IR结构、编译器只能解析int main { return 0; }时就开始从IR生成汇编代码,太过早打通链路,非必需的名词狂暴轰入大脑,反而让各个环节意义不明,起到了反作用。过早开始编写代码也导致整个教程中存在多次需要推翻重写的现象(Lv3推翻Lv1~2,Lv4.2推翻Lv3,Lv9.1推翻类型系统)。
接下来说说教程选择的编译目标。
-
一阶段输入SysY。SysY作为C子集,最大的好处是学生熟悉,无需过多解释语法语义。
然而SysY用于编译原理教学的坏处是多方面的:一方面,它继承了C大量在现代语言中不再常见的设计,语法复杂(变量与函数声明),语义混乱(常量与参数数组);另一方面,它从C中删除了浮点数、赋值表达式、随机数等功能,导致了一些教学和编程上的困难。示例程序mandelbrot.c通过外部库强行引入浮点数,输入和计算都无比别扭。不难想象用SysY编写光线追踪渲染器又会是怎样一幅美景。没有赋值表达式导致语法中没能出现右结合二元运算符,短路求值一节更是测无可测。
因为基本数据类型删到只剩一种,在数组出现之前,整个程序只可能出现唯一一种数据类型;直到最后,函数返回值都只可能是整型。这是真实编程语言中很难出现的情况,会导致架构决策错误。如果语言从一开始就同时支持整数和浮点数(且最好这两种数据类型大小不同)即可有效避免这一问题。
-
二阶段中间表示Koopa IR。教学用编译器采用IR没有合理动机,对教学会产生负面影响。
IR解决的关键问题——M + N和优化——在M = 1、N = 1、优化选做的教学编译器中是负收益。Koopa IR只提供了数据类型定义而没有其他功能,加上每章节都会打通前中后端,使用IR的体验成了纯粹走个过场。
在学生尚不熟悉的时机引入一套陌生的、两种形式的、本质上与教程最终目标无关的中间表示及其配套库,负担很大。学生不光要一边复习C++一边学RISC-V,还要研究Koopa IR库特有的使用方法,汤姆猫口吹喇叭脚拉提琴.gif
Koopa IR设计继承了LLVM IR的不少复杂性,数据类型定义与接口设计也多有不合理之处,使用起来很卡手。
如果将整个教程分为两部分,前半部分降级到IR,后半部分编译到汇编,能减少同时学习的概念数量并强行增加IR的存在感,但终究不能解决教学用IR缺乏动机的根本问题。也许像Let’s Build a Compiler的直肠编译法不是坏的,而是针对教学的优化。
-
三阶段输出RISC-V汇编。这是端水的选择。虽然总比某些还在教8086汇编的🪙课程好,但本质上仍与当今主流平台脱节,只不过一个是太过落后,一个是太过超前。
没有学生的电脑是RISC-V架构,编译出的程序只能用模拟器运行。结果机器码同IR一样,事实上都需要在专门环境下运行,完全没有“我的编译器产生的程序能被CPU直接运行”的感觉。
同样,因为评测机硬件不是RISC-V架构,只能用QEMU运行编译出的程序来测试性能,用模拟器里的运行速度评判编译器性能优化的好坏,这更是不科学的。
接下来讲讲实现用的语言。在跟着写了几次编译原理大作业后,我现在的观点是,编译原理课程选择用C/C++/Rust这类底层语言实现教学用编译器,除开学生经验背景因素,是完全不合理的。编译目标底层,不代表实现语言也应该底层。既然编译目标已经需要处理汇编,在实现中继续用底层语言只会加重认知负担,造成阻碍。
在许多课程中,编程实现是辅助理解的手段,就连处理对象是程序本身的编译原理也不例外。底层语言更像是需要设法学习理解的概念,难以成为思考的工具。然而大学课程大纲仍往往将C/C++作为第一门教学语言。在这种情况下,其他课程基于C/C++也无可厚非。但我认为这种情况整体上是不合理的,思维的工具应该是更高级的语言。
最后说说我的感受。从材料的完整度之高就能看出来,作者对编译原理及其教学有很大的热情。作者自己也说:
我的愿望是,让每个人都感受到写编译器的快乐。
虽说教程是作为学校课程实验部分的文档编写,但它的目光不局限于此。作者在教程中融入了诸多创新之处,例如兼容SSA的教学用IR、基于Docker的实验环境、为Rust提供头等支持等等,这总是值得肯定的。如果学生能因为Lisp in Lisp in SysY打开新世界的大门,这份心意也就传达到了。
与学校之外的其他资料相比,这套教程依旧有所缺陷。毕竟教程的核心对象读者仍为校内学生,这也是没办法的事。可惜在做过Crafting Interpreters之后,我对教程学习体验的阈值被提得很高。如果北大编译原理是我阅读的第一篇编译原理教程,我对它的评价也许会更高。
总结一下,北大编译原理课程实践作为MaxXing助教一手编制的用于学校教学的资料,用来自学的话显然不能与十年磨一剑的Crafting Interpreters相提并论。然而从课程教学的目的来看,在总体课程大纲和教学需求的限制之下,北大编译原理课程实践做到了优秀,是国内大学计算机传统课程中的一股清流。一门学校课程的实践部分能在校内外有如此高的知名度,就是它含金量最好的证明。
做测评不易,求大家关注+三连。我是satgo,我们下期作业见,886,886。
读到教程最后,我气笑了:
为什么学编译?
TODO: 待补充.